
Figure 1. Overview of FED-Bench. Representative samples from our benchmark covering seven basic emotions: happy, surprise, disgust, neutral, sad, fear, and angry.
Facial expression image editing requires fine-grained control to strictly preserve human identity and background while precisely manipulating expression. However, existing editing benchmarks primarily focus on general scenarios, lacking high-quality facial images and corresponding editing instructions. Furthermore, current evaluation metrics exhibit systemic biases in this task, often favoring lazy editing or overfit editing. To bridge these gaps, we propose FED-Bench, a comprehensive benchmark featuring rigorous testing and an accurate evaluation suite. First, we carefully construct a benchmark of 747 triplets through a cascaded and scalable pipeline, each comprising an original image, an editing instruction, and a ground-truth image for precise evaluation. Second, we introduce FED-Score, a cross-granularity evaluation protocol that disentangles assessment into three dimensions: Alignment for verifying instruction following, Fidelity for testing image quality and identity preservation, and Relative Expression Gain for quantifying the magnitude of expression changes, effectively mitigating the aforementioned evaluation biases. Third, we benchmark 18 image editing models, revealing that current approaches struggle to simultaneously achieve high fidelity and accurate expression manipulation, with fine-grained instruction following identified as the primary bottleneck. Finally, leveraging the scalable characteristic of introduced benchmark engine, we provide a 20k+ in-the-wild facial training set and demonstrate its effectiveness by fine-tuning a baseline model that achieves significant performance gains.
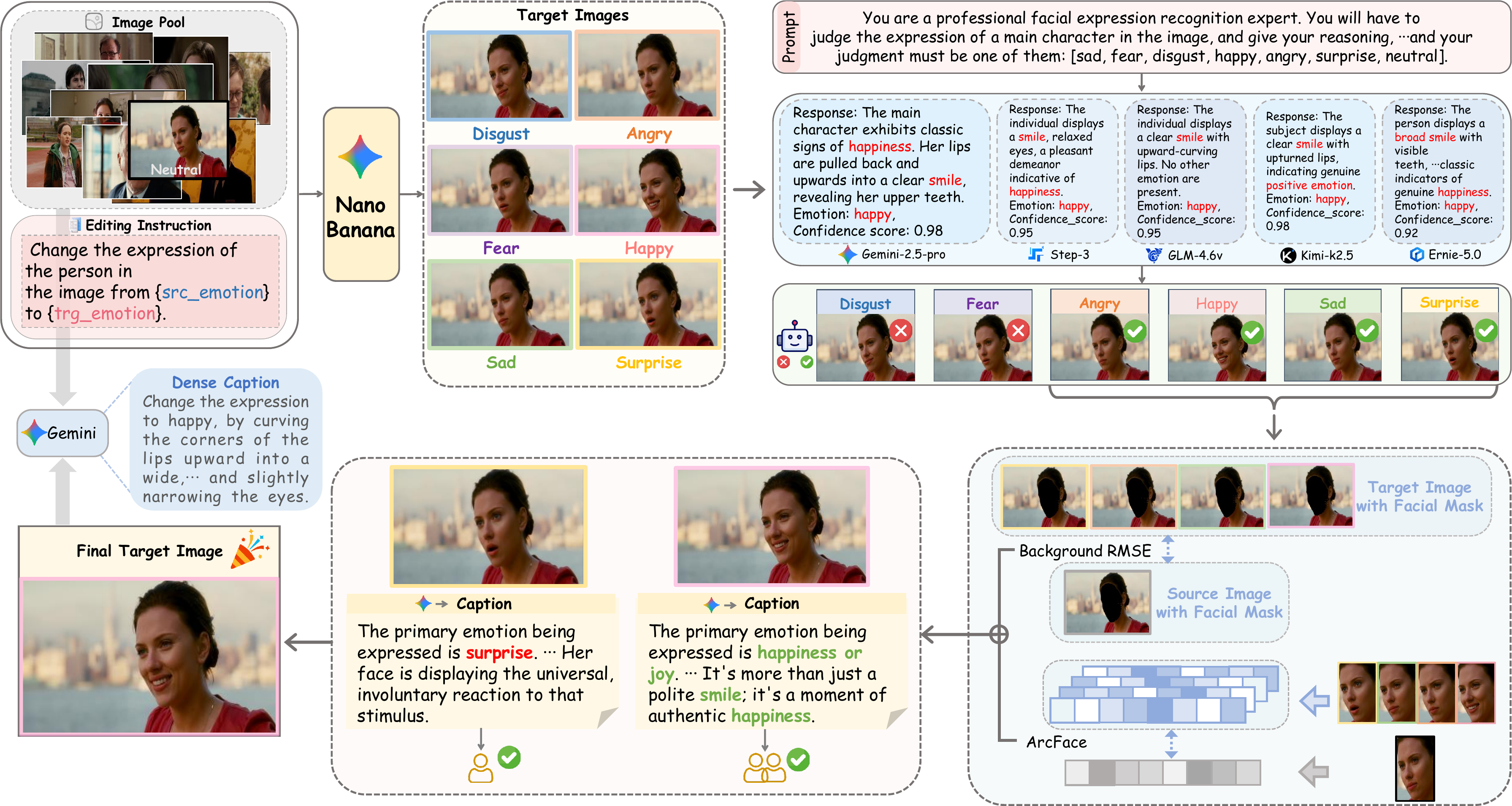
Figure 2. The overall illustration of FED-Bench construction pipeline.
To obtain high-quality Ground Truth images for refined evaluation, we design a rigorous multi-stage screening pipeline consisting of five stages:
We propose FED-Score, a decoupled evaluation protocol that integrates rule-based computations with the perceptual capabilities of MLLMs. The evaluation is explicitly decomposed into three dimensions:
Assesses whether the model faithfully preserves elements that should remain unchanged: Identity Preservation (ID) via ArcFace cosine similarity, Background Consistency (BG) via pixel-level RMSE in non-facial areas, and Perceptual Quality (PQ) via MLLM-based visual evaluation.
Evaluates how accurately the generated image executes editing instructions: Semantic Consistency (SC) judges the text-image matching degree, and GT-based Expression Alignment (GTA) directly compares the target with the reference Ground Truth expression.
Measures the actual magnitude of expression change relative to the expected change. A Gaussian penalty centered at 1.0 penalizes both lazy editing (insufficient change) and overfit editing (exaggerated distortion):
The three dimensions are integrated via multiplication, ensuring that all dimensions must be simultaneously satisfied:
Table 1. Benchmarking results on FED-Bench. Left: Dense instructions. Right: Simple instructions. BG↓: lower is better. REG: optimal at 1.0. Bold: best; underline: second best.
| Dense Instructions | Simple Instructions | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | ID | BG↓ | PQ | SC | GTA | REG | Score | Method | ID | BG↓ | PQ | SC | GTA | REG | Score |
| Qwen-Image-Edit-Plus | .58 | 17.5 | 9.7 | 8.8 | 5.7 | 1.18 | .469 | Qwen-Image-Edit-Plus | .63 | 16.8 | 9.8 | 8.8 | 5.8 | 1.13 | .492 |
| SeedDream 4.0 | .62 | 15.5 | 9.5 | 9.1 | 4.3 | 1.37 | .379 | SeedDream 4.0 | .69 | 16.4 | 9.7 | 8.0 | 5.0 | 1.26 | .413 |
| FLUX.2 Pro | .58 | 13.9 | 9.8 | 9.0 | 4.0 | 1.37 | .377 | FLUX.2 Pro | .58 | 14.0 | 9.6 | 8.8 | 5.2 | 1.37 | .400 |
| Qwen-Image-Edit | .45 | 19.6 | 9.3 | 8.9 | 4.2 | 1.37 | .337 | Qwen-Image-Edit-2511 | .44 | 15.3 | 9.8 | 9.4 | 4.0 | 1.42 | .361 |
| FLUX-Kontext-FED | .68 | 7.3 | 9.7 | 6.2 | 3.4 | 0.95 | .332 | Qwen-Image-Edit | .43 | 19.9 | 9.6 | 8.7 | 4.4 | 1.37 | .343 |
| FLUX-Kontext-Pro | .52 | 7.3 | 9.8 | 7.6 | 3.5 | 0.99 | .327 | Step1X v1p2 | .52 | 17.8 | 9.7 | 9.3 | 3.1 | 1.41 | .333 |
| FLUX-Kontext-Max | .50 | 9.7 | 9.7 | 7.7 | 3.5 | 1.07 | .320 | FLUX-Kontext-FED | .68 | 7.8 | 9.7 | 6.5 | 2.9 | 0.96 | .325 |
| Qwen-Image-Edit-2511 | .46 | 15.8 | 9.5 | 9.3 | 3.4 | 1.43 | .317 | FLUX-Kontext-Max | .49 | 8.1 | 9.9 | 5.2 | 3.7 | 1.03 | .259 |
| Step1X v1p2 | .56 | 17.1 | 9.4 | 7.7 | 3.0 | 1.31 | .303 | SeedEdit 3.0 | .48 | 12.8 | 9.1 | 7.6 | 2.7 | 1.56 | .239 |
| FLUX-Kontext-Dev | .72 | 23.8 | 9.6 | 6.7 | 3.0 | 0.67 | .243 | FLUX-Kontext-Pro | .55 | 8.5 | 9.9 | 4.8 | 3.4 | 0.97 | .227 |
| SeedEdit 3.0 | .49 | 11.6 | 7.8 | 7.4 | 1.9 | 1.55 | .203 | Bagel | .53 | 13.1 | 5.4 | 4.1 | 2.4 | 1.29 | .163 |
| UniWorld-v2 | .37 | 31.6 | 9.1 | 7.6 | 2.5 | 1.45 | .201 | Step1X | .32 | 17.3 | 9.7 | 5.6 | 2.3 | 1.67 | .149 |
| DreamOmni2 | .81 | 24.1 | 9.6 | 5.0 | 2.6 | 0.45 | .168 | OmniGen2 | .44 | 77.6 | 8.3 | 4.1 | 3.6 | 1.61 | .122 |
| OmniGen2 | .56 | 63.7 | 7.3 | 6.3 | 2.6 | 1.52 | .155 | FLUX-Kontext-Dev | .86 | 4.8 | 9.8 | 2.3 | 3.1 | 0.35 | .120 |
| FLUX-Kontext-Fill | .11 | 5.1 | 9.9 | 5.5 | 1.7 | 1.56 | .155 | UniWorld-v2 | .30 | 34.9 | 8.6 | 3.4 | 2.7 | 1.60 | .110 |
| Step1X | .33 | 16.3 | 7.3 | 6.9 | 1.3 | 1.72 | .127 | FLUX-Kontext-Fill | .11 | 5.1 | 9.7 | 3.3 | 1.1 | 1.52 | .096 |
| Bagel | .42 | 47.2 | 6.5 | 6.8 | 1.8 | 1.57 | .115 | DreamOmni2 | .45 | 36.9 | 8.9 | 1.2 | 2.0 | 1.40 | .049 |
| InstructPix2Pix | .08 | 47.0 | 0.0 | 0.0 | 0.0 | 2.56 | .001 | InstructPix2Pix | .08 | 41.2 | 0.2 | 0.1 | 0.1 | 2.42 | .004 |

Figure 3. Qualitative comparison of facial expression editing on FED-Bench. Each row shows a different editing task with the original image, ground truth target, and results from evaluated models.

Figure 4. Qualitative comparison of the FED-Score on two editing tasks.

Figure 5. Qualitative analysis of the REG metric on two editing tasks, illustrating lazy editing vs. overfit editing patterns.
@misc{xue2026fedbenchcrossgranularbenchmarkdisentangled,
title={FED-Bench: A Cross-Granular Benchmark for Disentangled Evaluation of Facial Expression Editing},
author={Fengjian Xue and Xuecheng Wu and Heli Sun and Yunyun Shi and Shi Chen and Liangyu Fu and Jinheng Xie and Dingkang Yang and Hao Wang and Junxiao Xue and Liang He},
year={2026},
eprint={2603.29697},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.29697},
}